I kept thinking about this while testing multimodal AI tools on architectural drawings.
We often say these models are getting good at “understanding images,” but floor plans are not ordinary images. They are dense, coded, layered drawings. To read them properly, you need to do more than recognize shapes. You need to notice room boundaries, circulation, relationships between spaces, levels of privacy, and overall layout logic. For architects, that feels natural. For AI, I was not so sure.
So I ran a small experiment.
I took one two-storey residential house plan and tested three multimodal AI models on it:
- ChatGPT Thinking
- Claude Sonnet 4.6
- Gemini Thinking
But I did not stop there. I also wanted to see whether the representation of the drawing changed the result. So I used the same plan in three versions:
- the original colored plan
- a grayscale version
- a masked / simplified color version
The question was simple: does AI understand architecture better from the original drawing, or from a cleaned-up version of it?
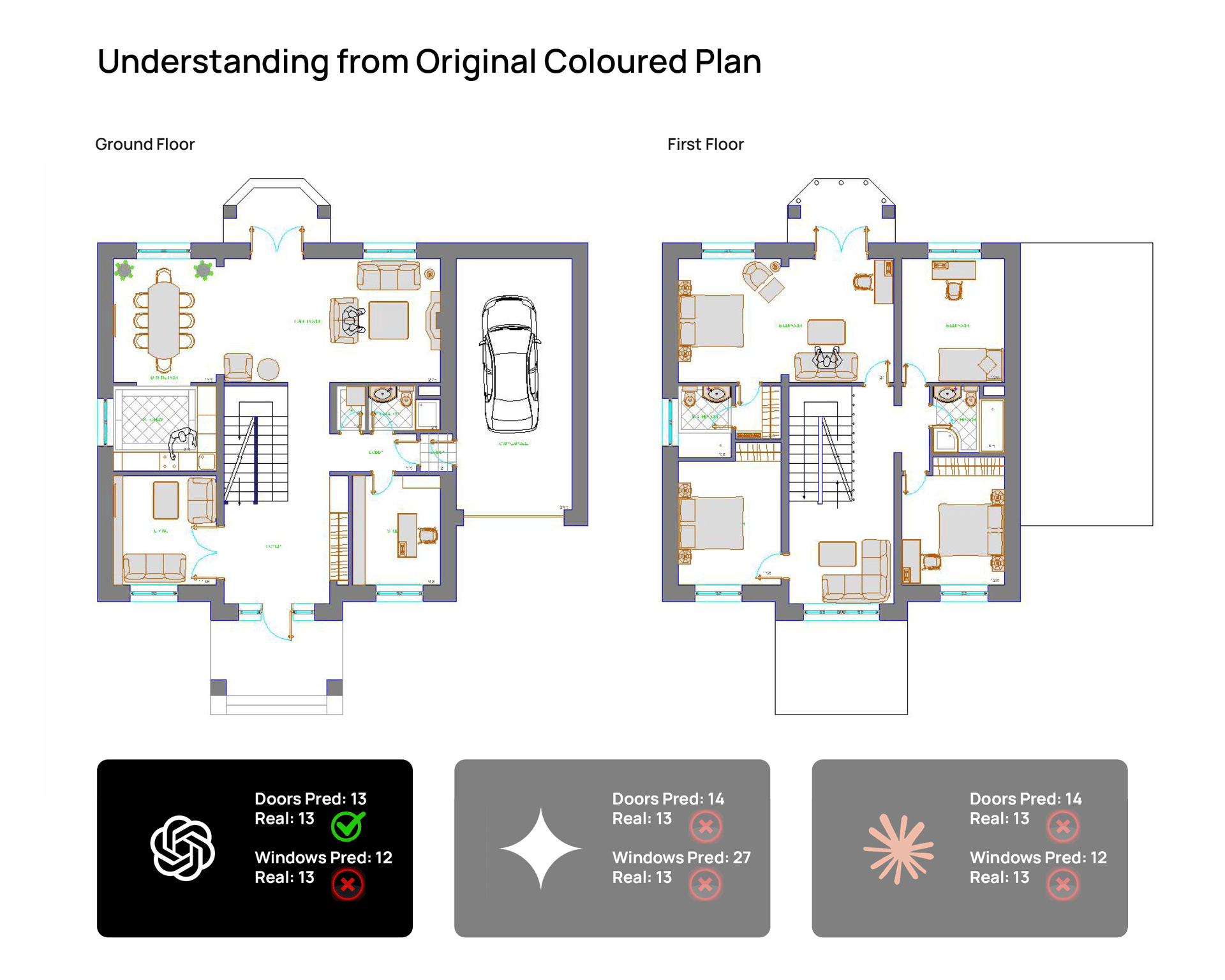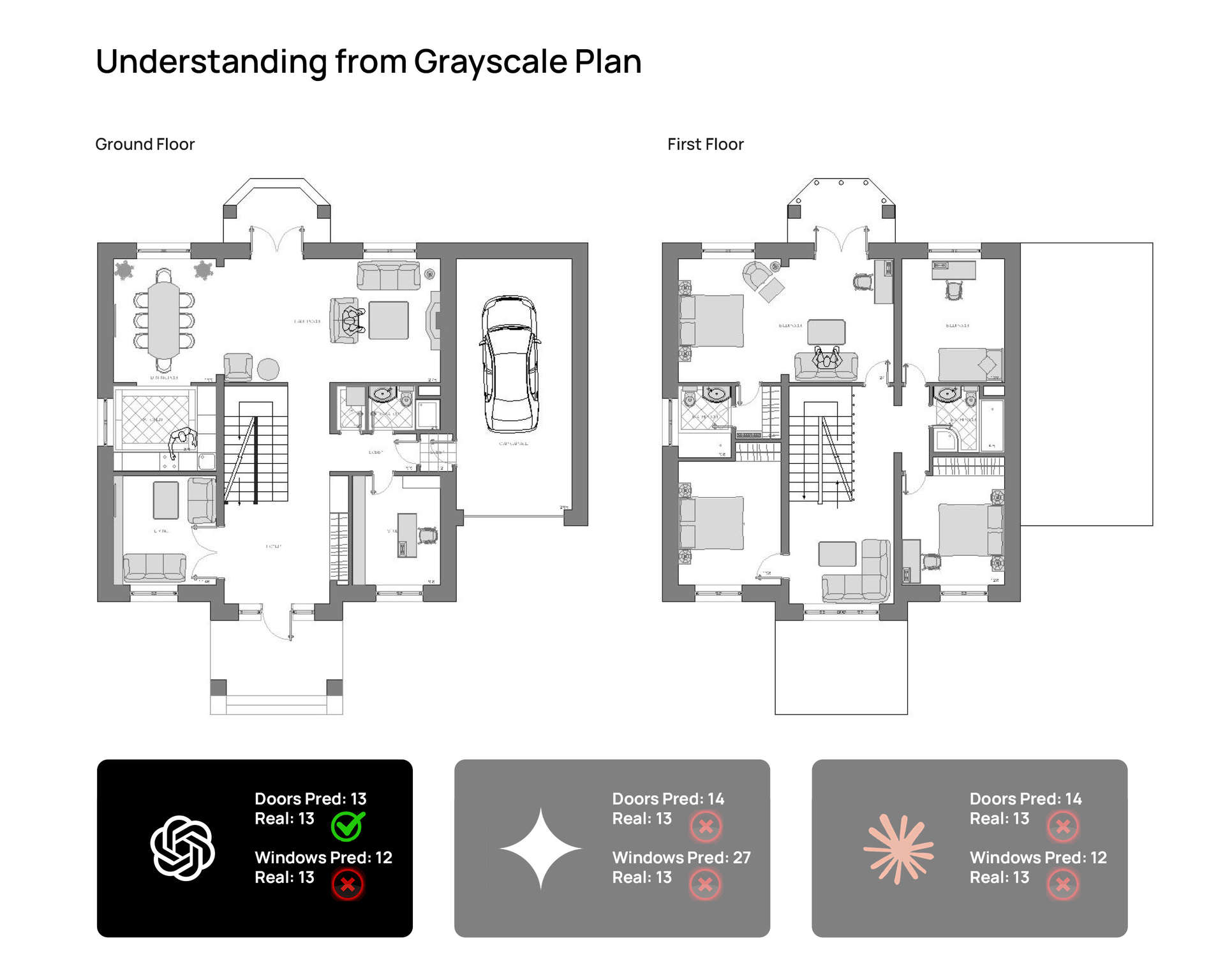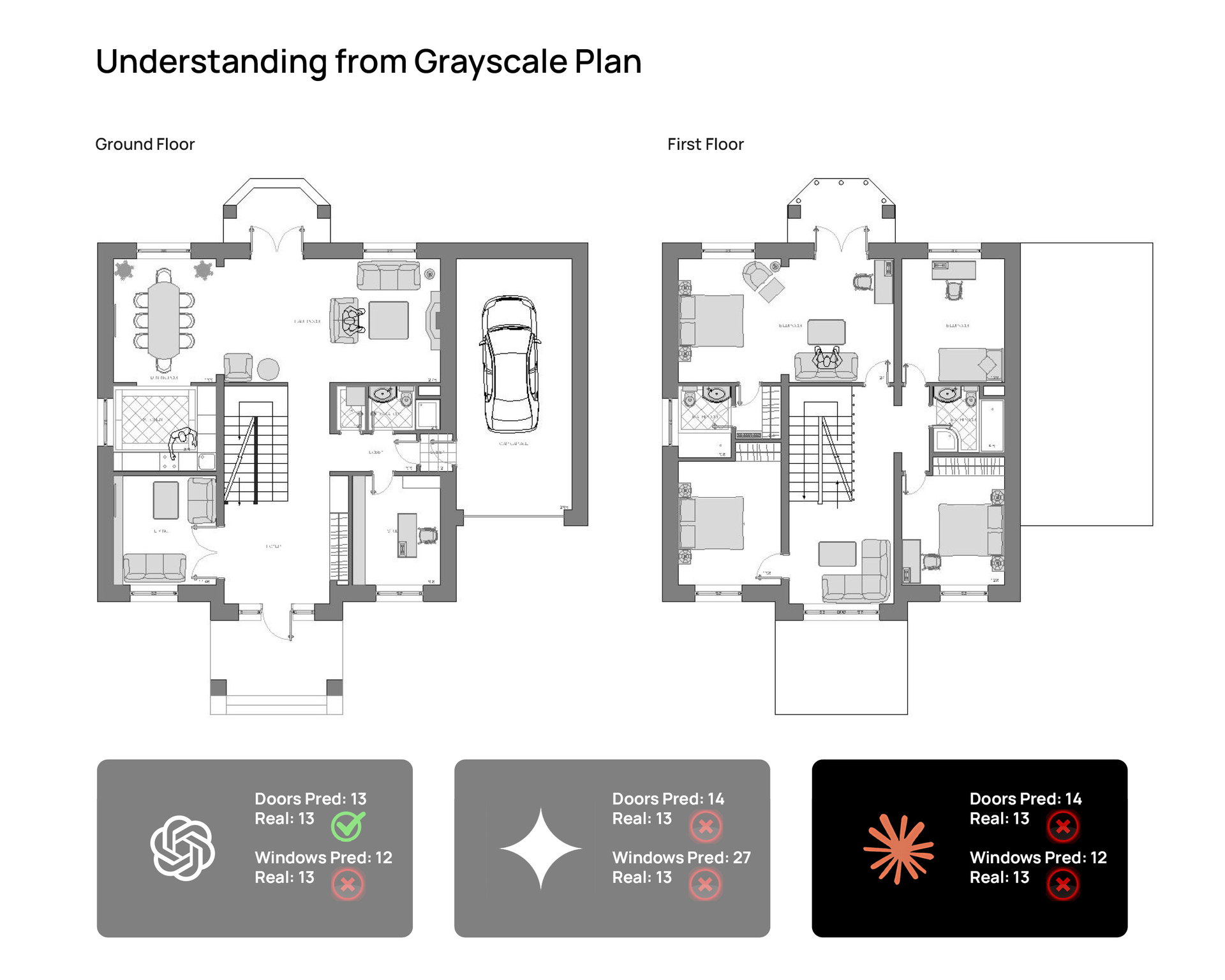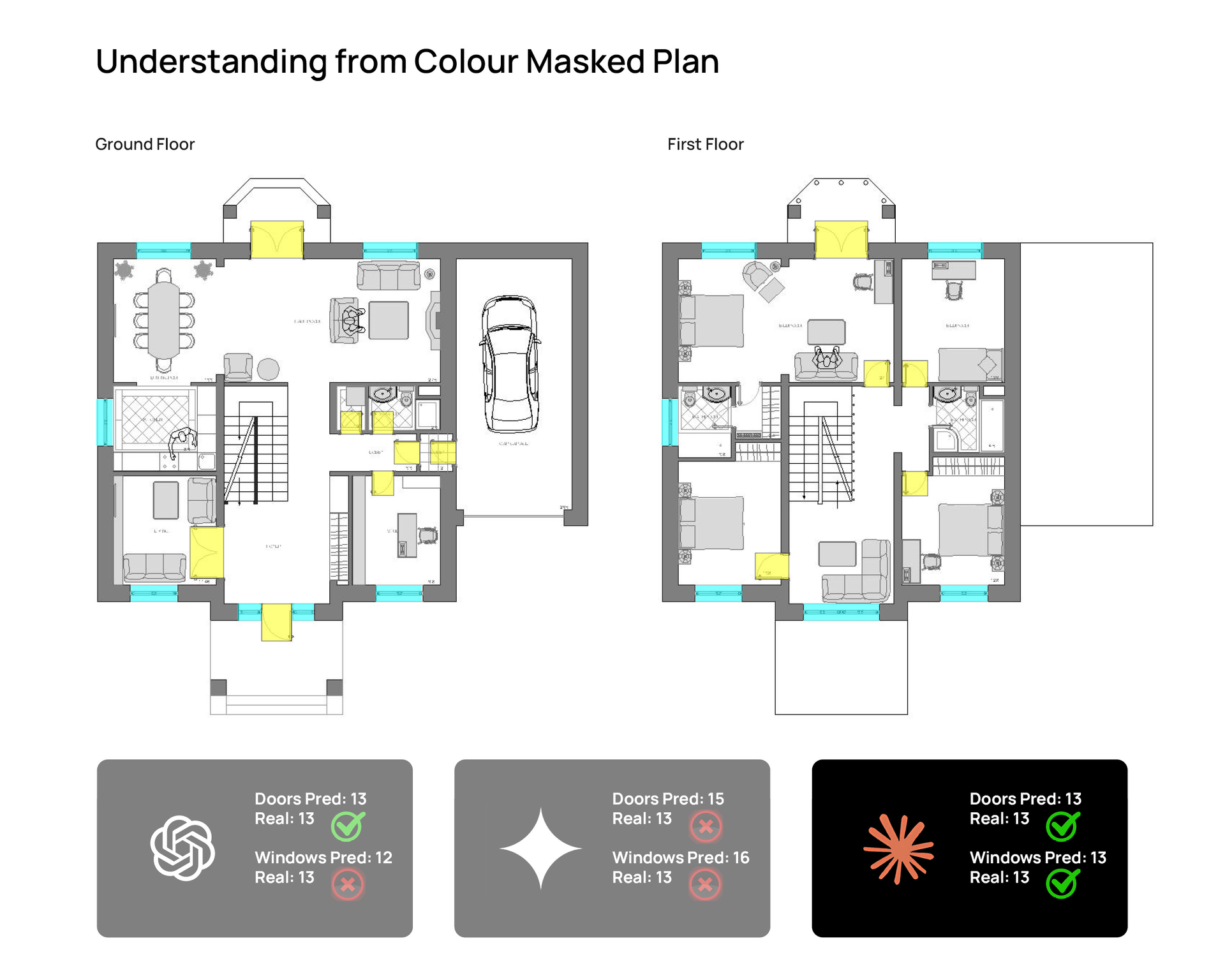
Animated comparison panel showing outputs from ChatGPT Thinking, Gemini Thinking, and Claude Sonnet 4.6 on
the same residential floor plan input. © Naveen Maria Fleming / ArchitectsWhoCode
What I asked the models
I kept the prompt structure the same for all three models and asked them for six outputs:
- number of doors
- number of windows
- building type
- level usage
- rooms present
- spatial organization
This gave me a mix of two things: counting and architectural interpretation.
That distinction turned out to matter a lot.
The ground truth
For this house plan, my reference reading was:
- 13 doors
- 13 windows
- residential two-storey house
- ground floor used for living / service / dining / garage
- first floor used for bedrooms / lounge / balcony
- rooms present: living room, dining, kitchen, bedrooms, bathrooms, garage, study, lounge, stairs
- spatial organization: central stair hall with rooms arranged around the perimeter
What I found
The first thing that became obvious was this:
all three models were better at reading the general logic of the house than at reading the exact drawing details.
They were usually quite good at saying that this was a residential house, that the upper level was more private, and that the plan was organized around a central stair or hall. In other words, they could often grasp the architectural idea of the plan.
But when it came to more precise things, especially counting windows, the performance dropped.
That surprised me a little, because it suggests that these models are not simply “bad at floor plans.” They are actually somewhat good at reading them at a high level. What they still struggle with is precision.
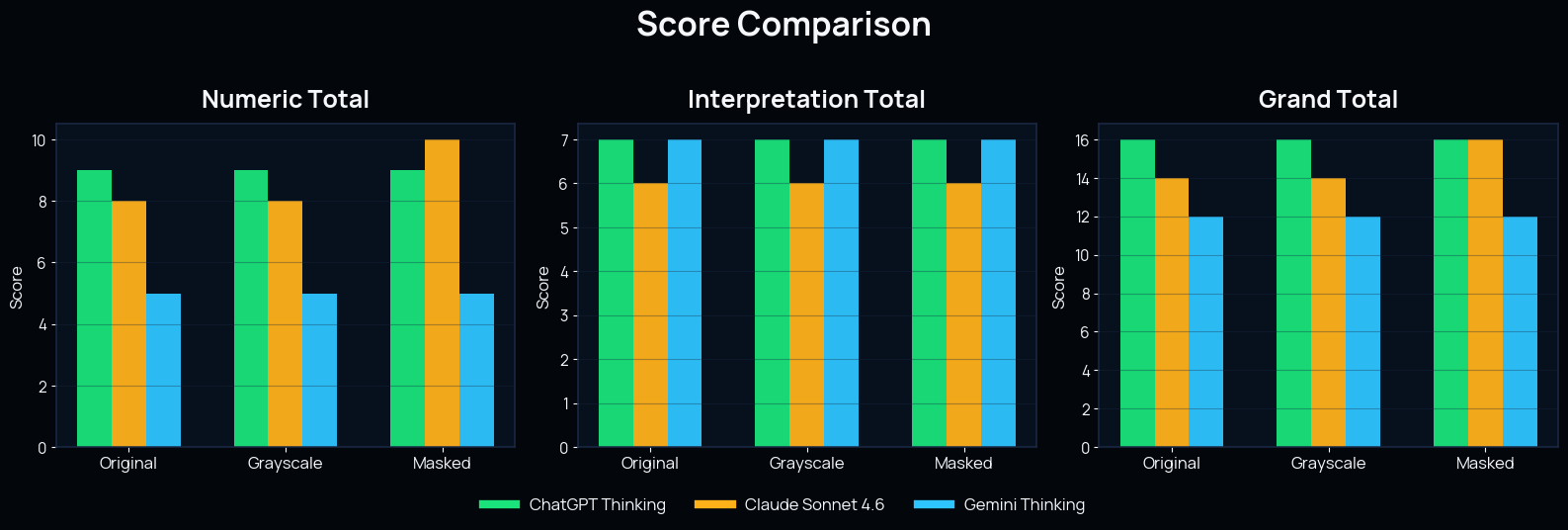
Comparison of numeric total, interpretation total, and grand total scores across the three AI models
© Naveen Maria Fleming / ArchitectsWhoCode
Model by model

Comparison of building type, level usage, rooms present, and spatial organization interpretation across the three AI models. © Naveen Maria Fleming / ArchitectsWhoCode
ChatGPT Thinking
ChatGPT was the most consistent across all three versions of the plan.
It got the door count right every time, stayed close on the window count, and gave strong answers for building type, rooms present, and overall spatial organization. It did not feel flashy, but it felt steady.
Its mistakes were relatively small. The most noticeable one was a slight undercount in windows and slightly simplified wording when describing floor usage.
Claude Sonnet 4.6
Claude was also quite solid, and it actually performed best on the masked plan. In that version, it matched both the door and window counts exactly.
It also did a good job describing the house as a detached residential type and understanding the separation between ground-floor living functions and upper-floor sleeping functions.
Where Claude felt weaker was in completeness. Some of its answers were correct in direction, but a bit compressed or simplified.
Gemini Thinking
Gemini was the least stable of the three.
It often understood the broad logic of the house, but it was much less reliable in detailed reading. The biggest issue was window counting, where it drifted far from the ground truth. It also added room interpretations like “gym” and “office,” which were not actually part of the reference reading.
That made Gemini the clearest example of something important in architectural AI use: hallucination does not always look absurd. Sometimes it looks plausible. And that is exactly why it is risky.
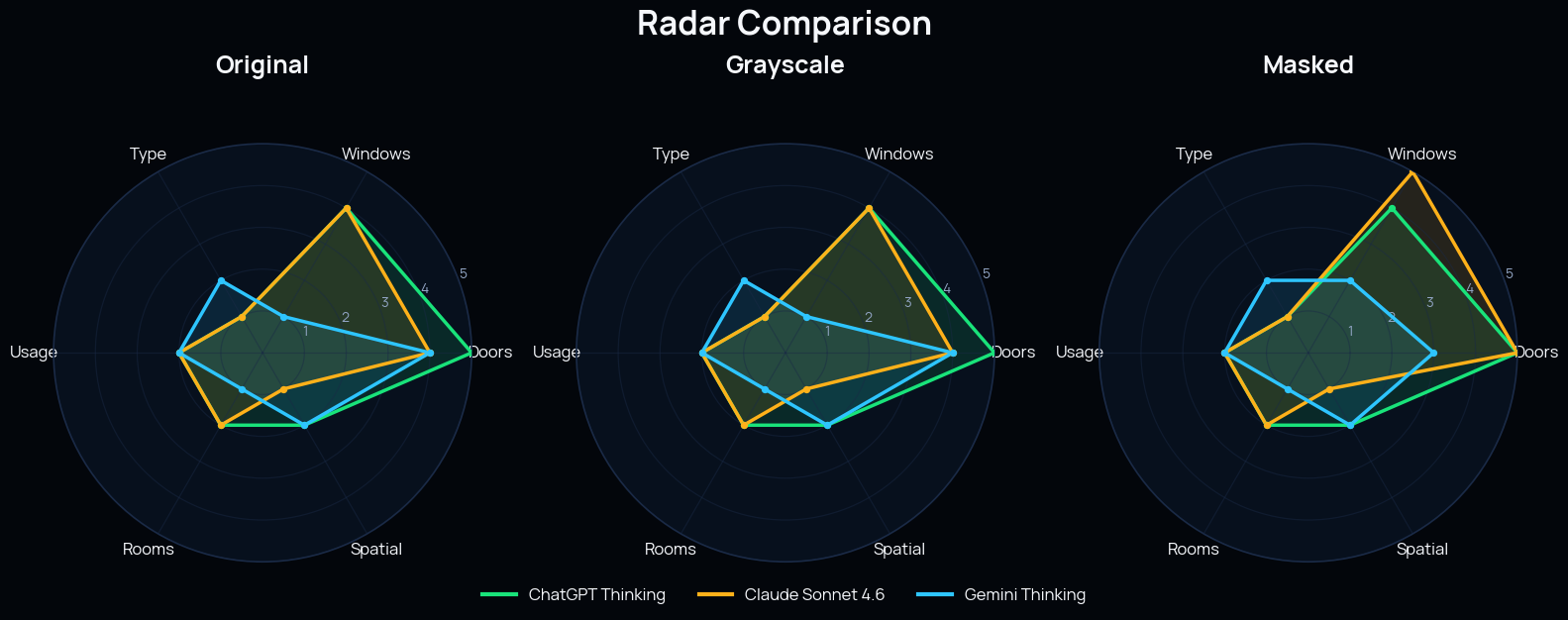
Radar chart visualizing comparative AI performance across key architectural reading categories for each plan representation
© Naveen Maria Fleming / ArchitectsWhoCode
The interesting part was not only the models
The more interesting result, honestly, was not just which model scored better.
It was that the same plan behaved differently depending on how it was represented.
Claude improved significantly on the masked version. ChatGPT stayed relatively stable across all three. Gemini did not benefit as much from simplification as I expected.
So the takeaway is not simply “simpler drawings are better for AI.” It is more specific than that:
representation matters, but different models respond to it differently.
That feels important for architecture, because it shifts the conversation. Instead of only asking, Which model is best? we might also need to ask, What kind of drawing helps a model reason better?

Heatmap showing the prediction error in door and window counts across original, grayscale, and masked plan representations
© Naveen Maria Fleming / ArchitectsWhoCode
Why this matters
If multimodal AI is going to be used in architecture, it probably will not begin by replacing technical review. It will begin in smaller, softer ways:
- quick layout summaries
- rough zoning interpretation
- first-pass spatial reading
- visual comparison tasks
- early-stage documentation support
And for those uses, this experiment suggests something encouraging: the models are already somewhat useful when the task is broad architectural interpretation.
But if the task depends on exact counts, exact classification, or detailed technical certainty, the human still needs to stay in the loop.
My takeaway
After running this benchmark, my conclusion is quite simple:
AI can read floor plans, but only up to a point.
Right now, it seems better at reading the logic of a plan than the precision of a plan.
That is still interesting. It means these tools may already have value in design workflows, but not in the way people often imagine. Their current strength is not exact technical reading. Their strength is approximate spatial interpretation.
And maybe that is enough to make them useful already, as long as we stay honest about the limits.
Final thought
The real question coming out of this was not “Which AI won?”
The real question was:
What kind of architectural representation gives AI the best chance of understanding a drawing well?
For me, that feels like the more useful direction for future testing.
Because if we want AI to work meaningfully with architecture, it may not be enough to improve the model. We may also need to rethink the way we present the drawing to the model in the first place.